Yafeng Yin’s research group has recently made new advancements in the field of sign language recognition. They have proposed a graph-based sign language processing architecture, which represents sign language sequences as graphs and then dynamically captures cross-region sign language features within and between frames based on the graph. The research can enhance the performance of sign language recognition and provide better communication and services for the deaf.
SignGraph: A Sign Sequence is Worth Graphs of Nodes.
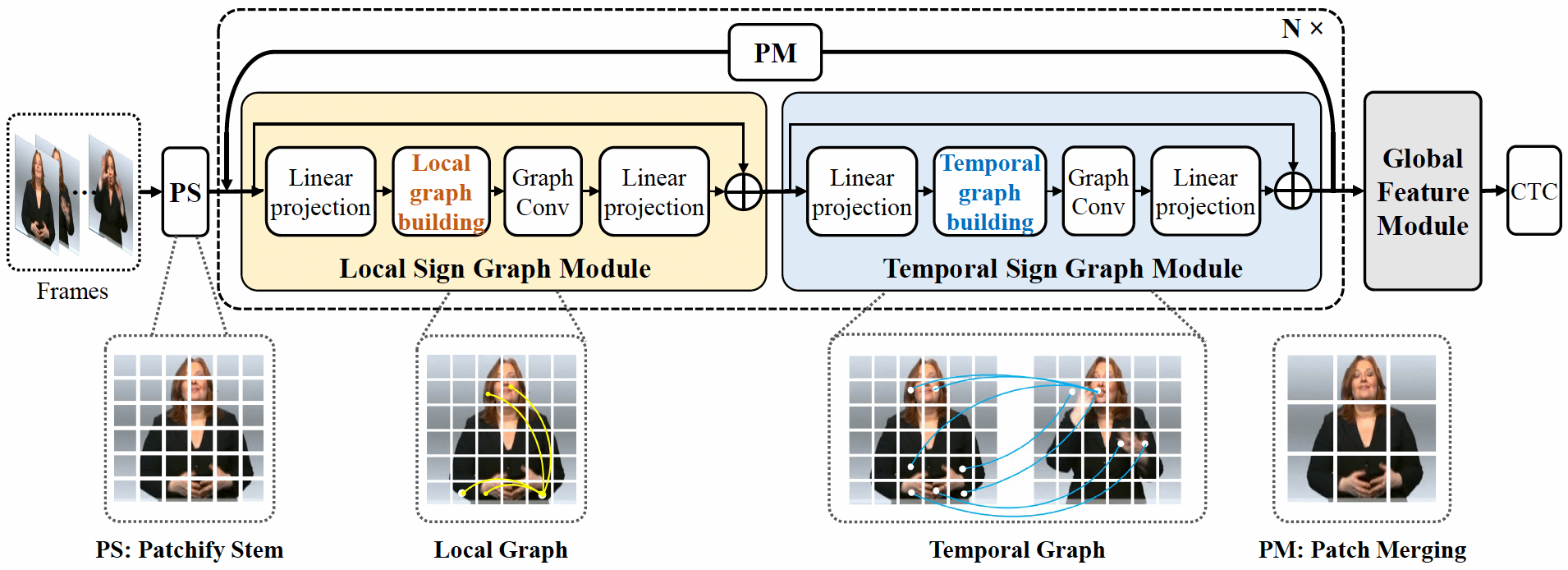
Despite the recent success of sign language research, the widely adopted CNN-based backbones are mainly migrated from other computer vision tasks, in which the contours and texture of objects are crucial for identifying objects. They usually treat sign frames as grids and may fail to capture effective cross-region features. In fact, sign language tasks need to focus on the correlation of different regions in one frame and the interaction of different regions among adjacent frames for identifying a sign sequence. Therefore, in their research work, they propose to represent a sign sequence as graphs and introduce a simple yet effective graph-based sign language processing architecture named SignGraph, to extract cross-region features at the graph level. SignGraph consists of two basic modules: Local Sign Graph (LSG) module for learning the correlation of intra-frame cross-region features in one frame and Temporal Sign Graph (TSG) module for tracking the interaction of inter-frame cross-region features among adjacent frames. With LSG and TSG, they build their model in a multiscale manner to ensure that the representation of nodes can capture cross-region features at different granularities. Extensive experiments on current public sign language datasets demonstrate the superiority of their SignGraph model. The model achieves very competitive performances with the SOTA model, while not using any extra cues.
This research work has been accepted for publication in The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) (CCF-A conference). Academic peers interested in this research are welcome to contact us for further discussions: yafeng@nju.edu.cn.


 中文
中文